 Last week, Amazon filed its first ever lawsuit over fake product reviews. It alleges that there is an entire ‘unhealthy ecosystem’ that has developed to falsely inflate the ratings of certain products on the Amazon sales platform.
Last week, Amazon filed its first ever lawsuit over fake product reviews. It alleges that there is an entire ‘unhealthy ecosystem’ that has developed to falsely inflate the ratings of certain products on the Amazon sales platform.
In this blog post, we’ve had a look at review fraud and thought about how sites can use graph visualisation to clamp down on the practice.
For more information about the uses of graph visualisation for anti-fraud, download our white paper.
What is Review Fraud?
Countless reviews are posted to the web everyday. Sites like eBay, Yelp, Foursquare and Amazon own huge volumes of user-generated review data that sits at the heart of their sales platforms. When used properly, this content acts as a useful tool – reassuring consumers that the product or service is credible and of a good quality (or, if the reviews are bad, warning them of the opposite).
Review fraud is when individuals or organizations manipulate that user-generated content to their own advantage – creating false reviews to misrepresent their business or competitors.
It’s illegal (lying to customers for sales), and a huge headache for users, the misrepresented businesses and the websites being used for the attacks.
For the websites, the review data is their future profit, driving both traffic and sales conversions. False reviews erode customer trust and damage the integrity of the data on which their brands are built. Websites cannot monetize their content if the consumers don’t trust its accuracy or validity.
For the companies being reviewed, there is a risk of huge reputation damage and lost revenue. False reviews paint an inaccurate picture, turning customers away from potentially good business and into the hands of less scrupulous suppliers.
As for the users, they are simply left not knowing who or what to believe.
Who commits Review Fraud?
There are three groups of people that commit review fraud:
- Business owners
- Disgruntled customers
- Black hat ‘reputation managers’
The third group use a mixture of brute force methods – systematically submitting reviews knowing that a few may slip through the anti-fraud processes – and more subtle approaches, like paying existing members to submit reviews from their own accounts.

Understanding Fraud Data
Detecting fraud is a matter of understanding patterns in connections – in this case, connections between people, devices, locations and reviews.
A key difference between Review Fraud and Financial Fraud is that review websites don’t always ask for verifiable information, e.g. an address, credit card number, etc. This increases the number of reviews submitted, but does make it impossible to crosscheck reviews against a watch list.
Instead we’re reliant on device data, location data and behavioral patterns, such as:
- Review text
- Review submission velocity
- Device fingerprints
- Profile data
- Geo-location data
Identifying fraudulent behavior
To find incidences of fraud, we need to do a few things:
- Identify different patterns of behavior
- Categorize ‘normal’ behavior and ‘outlier’ behavior
- Define which outlier behaviors indicate higher probability of fraud
Using an algorithmic approach, it’s possible to assign each piece of user-generated content with a fraud likelihood score. High-scoring content should be automatically blocked, low scoring content should be allowed, and borderline content would be manually reviewed using a KeyLines graph visualization application, built into the content management platform.
There are plenty of different behavior patterns that could indicate fraud. These will evolve over time as new techniques are developed, but some obvious patterns include:
- Creating a new account with a device that has already been used to access other accounts.
- Creating an account, leaving a single (very high or low) review, never returning.
- Reviewing a collection of businesses in one small area (e.g. all Italian restaurants in Cambridge) leaving a single excellent review and a series of 1* reviews for the rest.
Visualizing Review Fraud

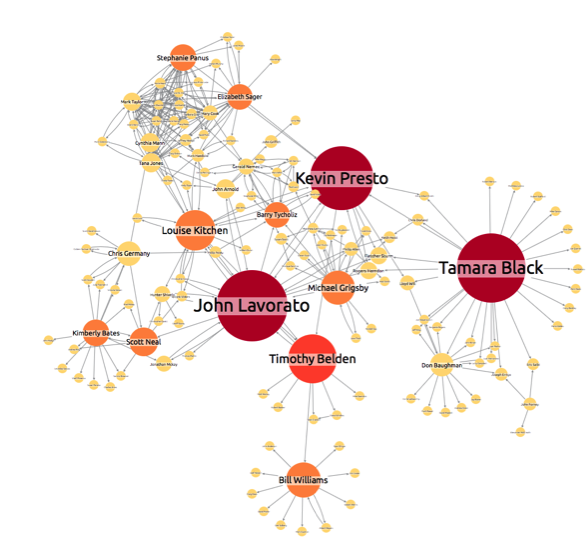
Each review is shown as a node with node color (red to green) indicating the review rating.
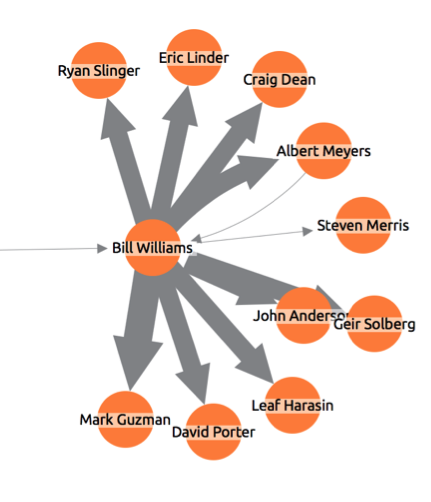
Associated with each review are three pieces of information: The business reviewed (building icon), the IP address used (computer icon), and the device provided (@ symbol icon). Reviews flagged by the system as suspicious use a heavy red link, instead of the default blue. Reviews previously removed as fraudulent show as ghosted red ‘X’ nodes.

One IP address has been used to submit seven reviews about a single business, using four different devices. Three reviews have already been removed as fake.
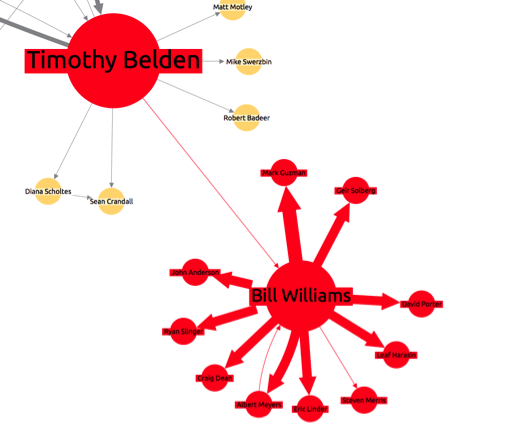
The timing and shared IP address of the remaining four means they are also likely to be false. If we expand outwards on one of the deleted reviews, we see more clues of a possible attempt to manipulate ratings:

This time, one device has been used to submit eight zero-star reviews about a single business, but using 5 different IP addresses (or, more likely, a proxy IP address).
This visualization approach provides a fast and intuitive way to digest large amounts of data, improving the quality and speed of decision-making.
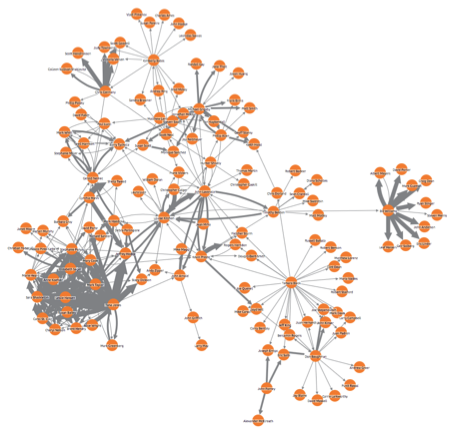
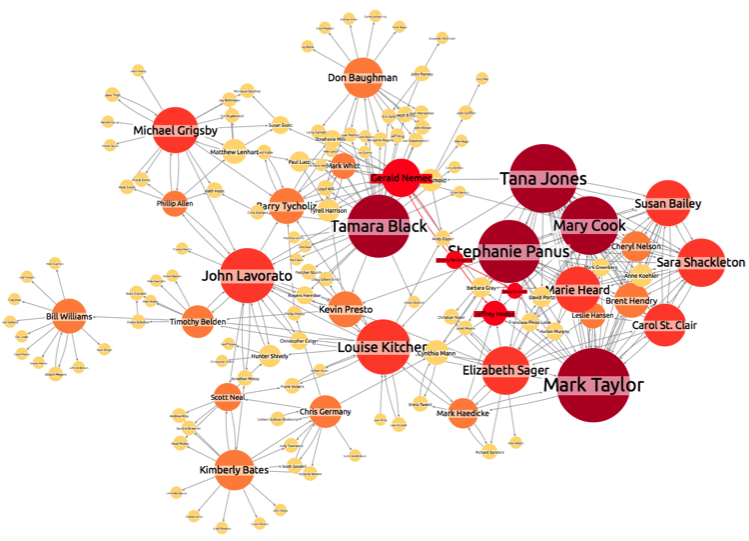
There are many different ways to model review data, depending on the insight you need to uncover. Below we have simply shown three elements of the data:
- The reviewers account (person nodes)
- The businesses being reviewed (building nodes)
- The review rating (green –> red links)

Again, patterns instantly begin to stand out – not least the incredibly positive reviewer in the bottom left who has left dozens of 5-star reviews for many different establishments. Could he be part of an ‘Astroturfing’ network? Looking at the timing of the reviews, and the locations of the businesses being reviewed, would give some good insight.
Also of interest is a cluster in the middle:

We need to question why one business has received multiple 1-star reviews from accounts that do not seem to have any other activity – a behavior we have identified as potentially indicating fraud.
These are just two possible ways of modeling and visualizing the data. Each approach will highlight different aspects and behaviors.
More about KeyLines
To find out more about KeyLines, or to learn how you could integrate a powerful web-based graph visualization component into your existing fraud-detection platform, just get in touch.
The post Clamping down on review fraud appeared first on .



 One of the great things about
One of the great things about 






 Visualizing OrientDB
Visualizing OrientDB Social connections dominate our lives. Networks of important people – politicians, business people, etc – have huge influence over the world we live in. For businesses, being able to understand these social networks of influential people can be the key to success.
Social connections dominate our lives. Networks of important people – politicians, business people, etc – have huge influence over the world we live in. For businesses, being able to understand these social networks of influential people can be the key to success. Last week, we were lucky enough to take part in the Cyber Innovation Zone at Infosec 2015. Our Product Manager, Ed Wood sums up his experience at Europe’s largest information security event.
Last week, we were lucky enough to take part in the Cyber Innovation Zone at Infosec 2015. Our Product Manager, Ed Wood sums up his experience at Europe’s largest information security event.


 Why have a static force-directed layout?
Why have a static force-directed layout?










 We’ve written before on this blog about the rise of the graph database.
We’ve written before on this blog about the rise of the graph database.

 One of the best things about KeyLines is its customization. Every aspect of a KeyLines application can be adapted to meet the needs of your users, and the peculiarities of their data.
One of the best things about KeyLines is its customization. Every aspect of a KeyLines application can be adapted to meet the needs of your users, and the peculiarities of their data.















